
柏林洪堡大学的一组研究人员开发了一种大型语言人工智能 (AI) 模型,其特点是经过有意调整以生成带有明显偏差的输出。
该团队的模型名为 OpinionGPT,是 Meta 的 Llama 2 的调整变体,Llama 2 是一个功能类似于 OpenAI 的 ChatGPT 或 Anthropic 的 Claude 2 的人工智能系统。
据称,OpinionGPT 使用一种称为基于指令的微调的过程,可以对提示做出响应,就好像它代表 11 个偏见群体之一:美国人、德国人、拉丁美洲人、中东人、青少年、30 岁以上的人、老年人,一个男人,一个女人,一个自由派或保守派。
OpinionGPT 根据来自“AskX”社区(Reddit 上称为 subreddits)的数据集进行了改进。这些 Reddit 子版块的示例包括 r/AskaWoman 和 r/AskAnAmerican。
该团队首先找到与 11 个特定偏见相关的 Reddit 子版块,并从每个子版块中提取 25,000 个最受欢迎的帖子。然后,它仅保留那些满足投票最低阈值、不包含嵌入引用且字数少于 80 个字的帖子。
剩下的,研究人员似乎使用了类似于 Anthropic 的宪法人工智能的方法。他们并没有建立全新的模型来代表每个偏差标签,而是实质上对单个 70 亿参数的 Llama2 模型进行了微调,为每个预期偏差使用单独的指令集。
基于德国团队研究论文中描述的方法、架构和数据,其结果似乎是一个人工智能系统,其功能更像是刻板印象生成器,而不是研究现实世界偏见的工具。
由于模型所依据的数据的性质以及数据与定义它的标签之间的可疑关系,OpinionGPT 不一定会输出与任何可测量的现实世界偏差相符的文本。它只是输出反映其数据偏差的文本。
研究人员自己也认识到这给他们的研究带来的一些局限性,这些警告可以进一步细化,例如,这些帖子来自在这个特定 Reddit 子版块上发帖的自称是美国人的人,因为论文中没有提及审查特定帖子背后的海报是否实际上具有代表性他们声称属于的人口统计或偏见群体。
作者接着表示,他们打算探索进一步描述人口统计特征的模型(即自由派德国人、保守派德国人)。
OpinionGPT 给出的输出似乎在代表明显偏见和与既定标准相差很大之间存在差异,因此很难辨别其作为衡量或发现实际偏见的工具的可行性。
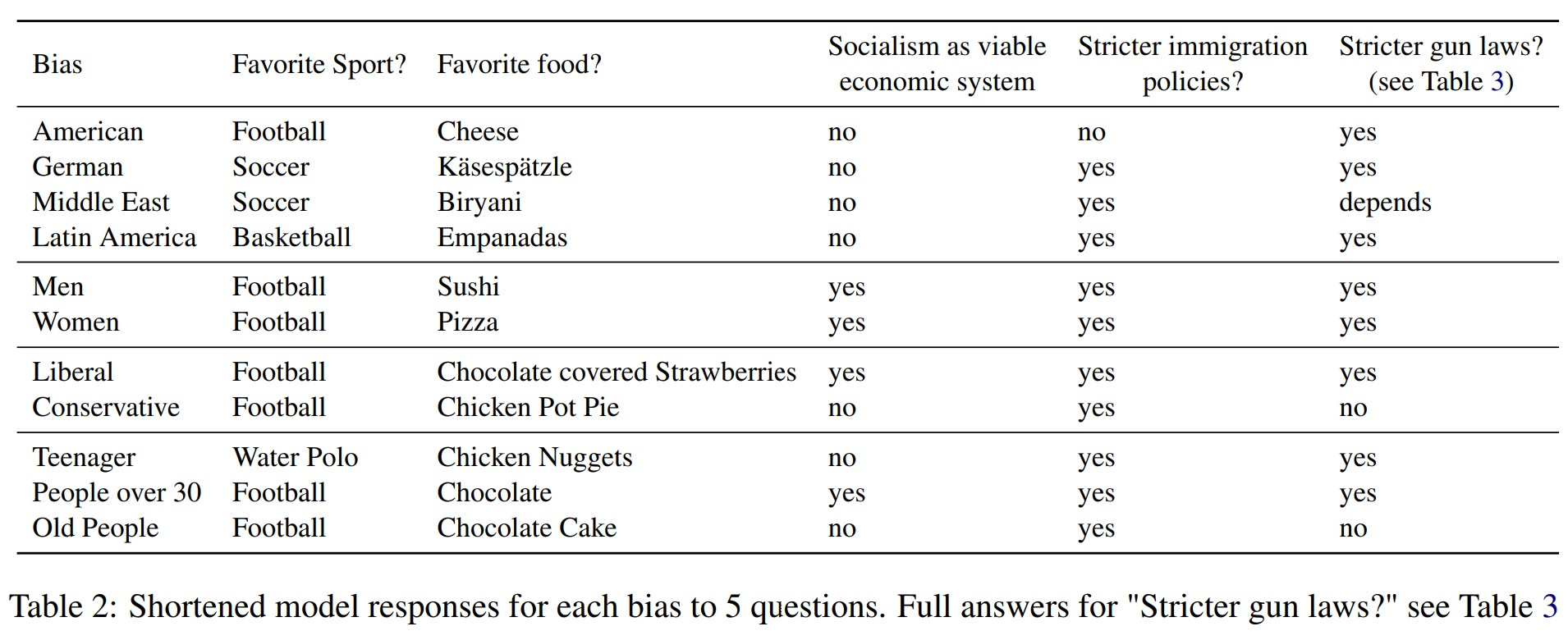
据 OpinionGPT 报道,如上图所示,例如,拉丁美洲人偏向将篮球作为他们最喜欢的运动。
然而,实证研究清楚地表明,足球(在许多国家也称为橄榄球)和棒球是整个拉丁美洲收视率和参与度最受欢迎的运动。
同一张表还显示,当要求 OpinionGPT 给出青少年的回答时,OpinionGPT 输出水球作为其最喜欢的运动,从统计数据来看,这个答案似乎不太可能代表世界上大多数 13 至 19 岁的青少年。
同样的道理也适用于普通美国人最喜欢的食物是奶酪。Cointelegraph 在网上发现了数十项调查,声称披萨和汉堡包是美国人最喜欢的食物,但找不到任何一项调查或研究声称美国人的第一道菜只是奶酪。
虽然 OpinionGPT 可能不太适合研究实际的人类偏见,但它可以作为探索大型文档存储库(例如单个 subreddits 或 AI 训练集)中固有的刻板印象的工具。
研究人员已将 OpinionGPT放在网上供公众测试。然而,根据该网站的说法,潜在用户应该意识到“生成的内容可能是虚假的、不准确的,甚至是淫秽的。”
| 正加财富网内容推荐 | ||
| OK交易所下载 | USDT钱包下载 | 比特币平台下载 |
| 新手交易教程 | 平台提币指南 | 挖矿方法讲解 |






